DCCL messages are encoded and decoded using a set of "field codecs" that are responsible for encoding and decoding a given field. The library comes with a default implementation for all the Google Protocol Buffers (Protobuf) types. It is also possible to define custom field codecs to encode one or more fields of a given message (or even the entire message).
Encoding algorithm
The following pseudo-code gives the process of encoding a DCCL message (using the dccl::v4::DefaultMessageCodec). Note this is not precisely how the actual C++ code works, but is rather given to explain the encoded message structure. DCCL messages are always encoded and decoded from the least significant bit to the most significant bit.
Definitions:
- Byte: exactly eight (8) bits
- Field: a numbered field in the Google Protobuf Message
- dccl::Bitset: A set of bits without byte boundaries. The front is the least significant bit, and the back is the most significant bit. Thus, appending to a Bitset means add these bits to the most significant bit.
Example Encoding
The following DCCL Message "CommandMessage" illustrates a basic command's DCCL definition, showing the components of the encoded message. Note: LSB = least significant byte, MSB = most significant byte.

An example of encoding the DCCL "CommandMessage" for a set of representative values is provided. The table displays the unencoded \(x\) and encoded \(x_{enc}\) values, according to the formulas in the Default Field Codec Reference. Below the table, the encoded message is shown in little endian format, in both hexadecimal and binary notations.

Decoding
Decoding is the reverse of encoding, with the requirement that each field codec consumes (reads) only the exact number of bits that the encoder produced. This allows the fields to be concatenated, and allows entire DCCL messages to be concatenated without any delimiters or other header data.
Default Field Codec Reference
You certainly don't need to know how the fields are encoded to use DCCL, but this may be of interest to those looking to optimize their usage of DCCL or to implement custom encoders. First we will casually introduce the default encoders, then you can reference "Table 2" below for precise details.
Remember that DCCL messages are always encoded and decoded from the least significant bit to the most significant bit.
Default Identifier Codec
Each DCCL message must have a unique numeric ID (defined using (dccl.msg).id = N). To interoperate with other groups, please see DcclIdTable. For private work, please use IDs 124-127 (one-byte) and 128-255 (two-byte).
This ID is used in lieu of the DCCL message name on the wire. It is encoded using a one- or two-byte value, allowing for a larger set of values to be used than a single byte would allow, but still preserving a set of one-byte identifiers for frequently sent messages. This is always the first 8 or 16 bits of the message so that the dccl::Codec knows which message to decode.
The first (least significant) bit of the ID determines if it is a one- or two-byte identifier. If the first bit is true, it's a two-byte identifier and the next 15 bits give the actual ID. If the first bit is false, the next 7 bits give the ID.
Two examples:
- One byte ID [0-128): (dccl.msg).id = 124. Decimal 124 is binary 1111100, which is appended to a single 0 bit to indicate a one-byte ID. Thus, the ID on the wire is 11111000 (or 124*2 = 248).
- Two byte ID [128-32768): (dccl.msg).id = 240. Decimal 240 is binary 0000000 11110000. This is appended to a single 1 bit to indicate a two-byte ID, giving an encoded ID of 00000001 11100001 (or 240*2+1 = 481).
Default Numeric Codec
Numeric values are all encoded essentially the same way. Integers are treated as floating point values with zero precision. Precision is defined as the number of decimal places to preserve (e.g. precision = 3 means round to the closest thousandth, precision = -1 means round to the closest tens). Thus, integer fields can also have negative precision, if desired. Fields are bounded by a minimum and maximum allowable value, based on the underlying source of the data.
To encode, the numeric value is rounded to the desired precision, and then multiplied by the appropriate power of ten to make it an integer. Then it is increased or decreased so that zero (0) represents the minimum encodable value. At this point, it is simply an unsigned integer. To encode the optional field's "not set", an additional value (not an additional bit) is reserved. To allow "not set" to be the zero (0) encoded value, all other values are incremented by one.
This default encoder assumes unset fields are rare. If you commonly have unset optional fields, you may want to use the PresenceBitCodec which uses a separate bit to indicate if a field is set or not. These are two extremes of the more general purpose idea of an entropy encoder, such as the arithmetic encoder. In that case, "not set" is simply another symbol that has a probability mass relative to the actual values to capture the frequency with which fields are set or not set.
For example:
The field takes 18 bits: \(\lceil \log_2(10000-(-10000) \cdot 10^1 + 1) \rceil = \lceil 17.61 \rceil = 18\).
Say we wanted to encode the value 10.56:
- Round to tenths: 10.6
- Subtract the minimum value: 10.6 - (-10000) = 10010.6
- Multiply by precision orders of magnitude: 10010.6*10 = 100106 = binary 01 10000111 00001010
Default Enumeration Codec
Enumerations are treated like unsigned integers, where the enumeration keys are given values based on the order they are declared (not the value given in the .proto file, unless packed_enum=false in which case the opposite is true).
For example:
In this case (for encoding): AUV is 0, USV is 1, SHIP is 2. After this mapping, the field is encoded exactly like an equivalent integer field (with max = 2, min = 0 in this case).
If packed_enum=false, the values are used as-is, and the field is encoded as an integer with max = 10, min = 3 (where values 4, 6, 7, 8, and 9 are unused).
Default Boolean Codec
Booleans are simple. If they are required, they are encoded with false = 0, true = 1. If they are optional, they are tribools with "not set" = 0, false = 1, true = 2.
Default String Codec
DCCLv3
Strings are given a maximum size in the proto file (max_length). A small integer (minimally sized like a required unsigned int field to encode 0 to max_length) is included first to specify the length of the following string. Then the string is encoded using the basic one-byte character values (ASCII).
For example:
Say we want to encode "HELLO":
- The string is length 5, so we insert 4 bits ( \(\lceil \log_2(10 + 1) \rceil = 4\)) with value 5: 0101
- Following, we add the ASCII values: 01001111 01001100 01001100 01000101 01001000
- The full encoded value is thus 0100 11110100 11000100 11000100 01010100 10000101
DCCLv4
See the VarBytesCodec below.
Default Bytes Codec
DCCLv3
Like the string codec, but not variable length. It always takes max_length bytes in the message, and if it is optional, a presence bit is added at the front. If the presence bit is false, the bytes are omitted.
DCCLv4
See the VarBytesCodec below.
Default Message Codec
Sub-messages are encoded recursively. In the case of an optional message, a presence bit is added before the message fields. If the presence bit is false (indicating the message is not set), no further bits are used.
Mathematical formulas for Default Field Codecs
DCCLv3
See Table 1 in the IDL for symbol definitions. The formulas below in Table 2 refer to DCCLv3 defaults (i.e. codec_version = 3 which is equivalent to codec = "dccl.default3"). A few things that may make it easier to read this table:
- Left bit-shifting by N bits ( \(x << N\)) is equivalent to multiplying by powers of two to the N ( \(x \cdot 2^N\)).
- \(\lceil \hbox{log}_2(b-a+1) \rceil\) is the fewest number of bits that can hold all the values between \(a\) and \(b\). For example, \(a=0\) through \(b=7\) can be stored in 3 ( \(\lceil \hbox{log}_2(7-0+1) \rceil\)) bits. Even if \(b\) was 4, 5, or 6, it would still take 3 bits since you cannot have partial bits, hence the ceiling function ( \(\lceil \ldots \rceil\)).
- Appending bits in this context means adding these bits to the most signficant end (the left side if the bits are written MSB to LSB from left to right). For example, appending a Bitset of size 2 with decimal value 3 (b11) to a Bitset of size 3 with decimal value 1 (b001) would yield a Bitset of size 5 with value 25 (b11001). This is equivalent to the mathematical expression \(1+3\cdot 2^3 = 25\)
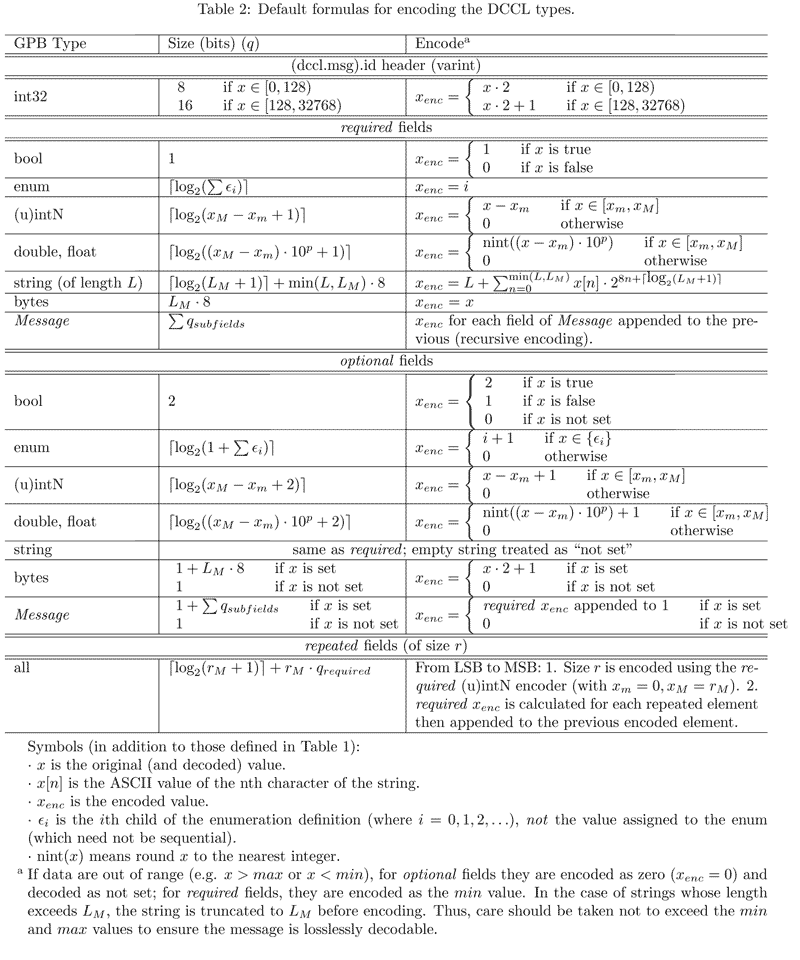
DCCLv4
The DCCLv4 Default Field Codecs are identical to those from DCCLv3 (see Table 2 above), except for the string and bytes types, which use the VarBytesCodec described below for both types.
The resolution option for encoding numeric types is not captured in Table 2 but is analogous to the power of 10 case (precision). For further details see dccl/codecs2/field_codec_default.h
Additional Built-in Codecs
In addition to the default codecs, the DCCL library provides a number of built-in codecs for certain data types or use cases.
VarBytesCodec (string / bytes)
This codec is now the default for bytes and string fields since DCCLv4 (codec_version = 4). In DCCLv3 this codec can be enabled by setting the field option (dccl.field).codec="dccl.var_bytes" on a string or bytes field.
This codec starts with a presence bit only if the field is optional. This is followed by a prefix integer encoding the length of the string or bytes. The size of the prefix field is exactly the number of bits needed to encode the values 0 through max_repeat. Finally the actual string (as ASCII) or bytes are appended to the Bitset to produce the complete message.
| GPB Type | Size (bits) (q) | Encode |
|---|---|---|
| required fields | ||
| string / bytes (of length \(L\)) | \( \lceil \hbox{log}_2(L_M + 1) \rceil + \text{min}(L, L_M) \cdot 8 \) | \(x_{enc} = \text{min}(L, L_M) + \sum_{n=0}^{\text{min}(L, L_M)} x[n] \cdot 2^{8n+\lceil \hbox{log}_2(L_M + 1)\rceil}\) |
| optional fields | ||
| string / bytes (of length \(L\)) | \(\begin{array}{l l} 1 + \lceil \hbox{log}_2(L_M + 1) \rceil + \text{min}(L, L_M) \cdot 8 & \quad \text{if $x$ is set} \\ 1 & \quad \text{if $x$ is not set}\\ \end{array} \) | \(x_{enc} = \left\{ \begin{array}{l l} 1+ \text{min}(L, L_M) \cdot 2 + \sum_{n=0}^{\text{min}(L, L_M)} x[n] \cdot 2^{8n+\lceil \hbox{log}_2(L_M + 1)\rceil + 1} & \quad \text{if $x$ is set }\\ 0 & \quad \text{if $x$ is not set} \ \end{array} \right.\) |
PresenceBitCodec (all types)
This codec is designed to use less space on average for optional fields that are often left unset. This is in contrast to the numeric default field codec which uses the same amount of space for an unset message as a set message. Thus, if your optional field most often has a value set, it is better to use the default codec than this one.
This codec wraps all the default field codecs explained above. For required fields this is identical to the default field codec. For optional fields, an additional bit is added to the Bitset (the "presence bit"). If this bit it set, the rest of the bitset is comprised of the normal required encoding for the given default field codec (that is, \(x_{enc}^{default/required}\) shown below is the value of \(x_{enc}\) for the given field type for a required field in Table 2). If it is not set, no additional bits are added so the field only uses 1 bit in the encoded message.
To enable this codec, use (dccl.field).codec="dccl.presence" for a particular field or to enable for all fields in the message, use (dccl.msg).codec_group = "dccl.presence".
| GPB Type | Size (bits) (q) | Encode |
|---|---|---|
| required fields same as default field codec | ||
| optional fields | ||
| any | \(\begin{array}{l l} 1 + q_{default/required} & \quad \text{if $x$ is set} \\ 1 & \quad \text{if $x$ is not set}\\ \end{array} \) | \(x_{enc} = \left\{ \begin{array}{l l} 1+ x_{enc}^{default/required} \cdot 2 & \quad \text{if $x$ is set }\\ 0 & \quad \text{if $x$ is not set} \ \end{array} \right.\) |
TimeCodec (uint64, int64, double)
This special purpose codec is designed to encode a UNIX timestamp (seconds or microseconds since 1970-01-01 midnight UTC) in an efficient manner by assuming the message will be received and decoded within some number of days ((dccl.field).num_days) after transmission. Since in general we cannot assume system clocks are synchronized (and thus the receiver clock may have an earlier time than the sender clock), this codec centers the encoded time in the middle of the num_days range. This means, for example, that if num_days=1 (the default), any message timestamped by the sender within +/- 0.5 days (12 hours) of the clock of the receiver upon decoding will be correctly decoded. If this range is exceeded, the wrong timestamp will be decoded.
As this codec predates the DCCL Static Units functionality, this codec will convert using microseconds or seconds based on the type of the field (double = seconds, (u)int64 = microseconds). Thus, please note that this codec does not examine the (dccl.field).units values to determine the conversion factor. So when using this codec, the correct units specification (if using) must be:
You can set the precision / resolution to control the desired time resolution (defaults to resolution = 1 second).
StaticFieldCodec (all types)
This codec doesn't take any space on the wire (size = 0 bits), but rather simply always sets this field on decoding to the (dccl.field).static_value (converted to the field type using C++ iostream) specified in the message. It can be enabled by setting (dccl.field).codec = "dccl.static".
The value of the field (if set) on encoding is ignored.
HashCodec (uint32)
In order to provide the best compression possible, DCCL requires that the message definition (.proto file) be identical between sender and receiver. To help the developer or user verify this, each DCCL type has a hash value that can be used to determine if the contents of the .proto file has changed in a way as to be incompatible with previous versions.
This hash value is returned by the dccl::Codec::load() method for compile time verification, or can be included in the message itself using this HashCodec for runtime verification.
This codec uses the Default Numeric Codec to encode the hash value, where (dccl.field).min must be 0 and (dccl.field).max is a power of 2 minus 1 up to uint32 (2^32 -1 = 4294967295). This allows the user of this codec to select the desired length of hash (up to 32 bits) to tradeoff message size versus hash collision probability.
The value of this field (if set) on encoding is ignored, and overwritten with the computed hash of the message at the encoder. The decoder computes the hash of the message and throws an exception if this does not match the hash transmitted in the message (indicating that the sender and receiver do not have compatible versions of the message).
Additional Codec libraries
DCCL also includes several add-on libraries that provide special purpose codecs that are not loaded by default but can be used by loading the appropriate add-on library and setting the required options.
Native Protobuf
This codec library allows a DCCL user to use the standard native Protobuf encoding for a given field for some or all of a DCCL message. Please note that this does not mean the entire message is compatible with the Protobuf encoding, as DCCL still provides efficiencies (at the cost of message backwards compatibility) by removing field IDs and other Protobuf encoding features.
This codec is best used when you want some of the efficiency of DCCL but do not have the need or time to set the bounds required by the DCCL default field codecs. These Protobuf codecs will take up more space than the DCCL default codecs, but the programmer does not have to set min, max, and precision bounds.
This codec is implemented for all the field types except string and bytes. For repeated fields (dccl.field).max_repeat must be set as usual. This ensures the maximum size of the message is always known, as per DCCL requirements.
To enable this codec, use (dccl.field).codec="dccl.native_protobuf" for a particular field or to enable for all fields in the message, use (dccl.msg).codec_group = "dccl.native_protobuf". In addition, the libdccl_native_protobuf.so library needs to be loaded by dccl::Codec::load_library.
Arithmetic Coder
Arithmetic coding is a type of entropy encoding that uses a probability distribution (for the symbols in use) to nearly optimally encode messages that match the distribution. It is a generalized form of Huffman coding. This DCCL default numeric codec for required fields can be thought of as an arithmetic coder with a uniform probability distribution between (dccl.field).min and (dccl.field).max.
The DCCL arithmetic coder library is adapted from the reference code provided by Witten et al. "Arithmetic Coding for Data Compression," Communications of the ACM, June 1987, Vol 30, Number 6. The main difference is that the DCCL implementation ensures a known message size even at the end-of-file (end of message) so that the DCCL Arithmetic Coder consumes the exact correct number of bytes allowing following fields (or concatenated DCCL messages) to be correctly decoded.
Using the Arithmetic Coder can be difficult and time consuming, but the reward is extremely compact messages in the case where the source data probability distribution is can be well modeled.
To enable this codec, use (dccl.field).codec="dccl.arithmetic" for a particular field and set the (dccl.field).(arithmetic).model = "somemodel" to the model (probability distribution) to use for this field. The model (defined using the Protobuf message dccl::arith::protobuf::ArithmeticModel) must be loaded using dccl::arith::ModelManager::set_model() for the given name (e.g., "somemodel") used in the DCCL message definition.
Both sender and receiver must use the same model. You can use an adaptive model (ArithmeticModel::is_adaptive == true) where the probability distribution changes based on the actual probabilities experienced. In this case all messages must be encoded and decoded in the same order to ensure the sender and receiver have the same model. This requires a protocol that ensures reception and drops duplicate packets.
Look at dccl_arithmetic/test.cpp and dccl_arithmetic/test_arithmetic.proto for some usage examples.
REMUS CCL
This special purpose codec library provides DCCL interoperability and decoding functionality with the CCL (REMUS vehicle) set of messages. While they have a similar name, CCL and DCCL are unrelated projects and do not have a common code base or set of developers. When using DCCL with CCL, normal DCCL messages are prefixed with the CCL byte value 32, which has been registered with WHOI.
For more information look at the unit tests in dccl_ccl/test.cpp and dccl_ccl/test.proto and at the DCCL equivalents of the core CCL message types in dccl/ccl/protobuf/ccl.proto.
Custom Field Codecs
To write your own codecs:
- Subclass one of the base classes dccl::TypedFixedFieldCodec, dccl::TypedFieldCodec or dccl::RepeatedTypedFieldCodec
- Add the class into the dccl::Codec's manager (dccl::FieldCodecManagerLocal) with a given string name, e.g.,
dccl::Codec codec; codec.manager().add<MyFieldCodec>("my_field_codec") - Set a given field's
(dccl.field).codecto the name given to the dccl::Codec's manager (e.g.,(dccl.field).codec = "my_field_codec"), or the(dccl.msg).codecto change the entire message's field codec. Or you can use(dccl.msg).codec_groupto set the codec for the message and all fields within it. In this last case, the codec must be defined for all types within the message, and the message itself.
See also:
